
Diese Frage stellen mir Integratoren, die Perimetersicherheitsprojekte planen, sehr oft. Die Antwort ist wichtig, da sie sich direkt auf Ihre Fehlalarmrate5 und das Vertrauen Ihres Kunden auswirkt.
Unser System verlässt sich nicht auf ein einzelnes Modell. Es verwendet einen Ansatz zur Fusion mehrerer Merkmale, der Folgendes kombiniert: Vollkörpererkennung8 zur Zielerfassung über große Entfernungen, ein Kopf-Schulter-Modell zur Filterung von Nahbereichs-Fehlalarmen und Re-ID zur kontinuierlichen Verfolgung über Okklusionen hinweg. Jede Ebene übernimmt eine andere Aufgabe.
 Personenerkennung PTZ-Kamera KI-Algorithmus
Personenerkennung PTZ-Kamera KI-Algorithmus
Im Folgenden erläutere ich, wie jede Erkennungsebene in realen Einsätzen funktioniert, wann jedes Modell Vorrang hat und wie Sie den Algorithmus für Ihre spezifische Projektumgebung optimieren können. Lassen Sie mich Ihnen die Details erläutern.
Inhaltsübersicht
Kann die Kamera eine sitzende oder kriechende Person auf dem Boden genau identifizieren?
Das ist ein echtes Problem. Auf Baustellen und Bauernhöfen stehen Menschen nicht immer aufrecht. Wenn Ihre Kamera nur nach einer stehenden menschlichen Form sucht, verpasst sie kritische Ereignisse.
Ja, die Kamera kann eine sitzende oder kriechende Person erkennen. Das Vollkörpererkennungsmodell verwendet eine CNN, die auf Tausenden von nicht standardmäßigen Körperhaltungen trainiert wurde. Sie erkennt menschliche geometrische Proportionen und Gliedmaßenverhältnisse, nicht nur eine aufrechte Silhouette. Wenn die Körperhaltung mehrdeutig ist, greift das Kopf-Schulter-Modell als sekundäre Überprüfung ein.
 Personenerkennung sitzend kriechend PTZ-Kamera
Personenerkennung sitzend kriechend PTZ-Kamera
Wie die Vollkörpererkennung nicht standardmäßige Körperhaltungen handhabt
Das Vollkörpermodell sucht nicht nach einer einzelnen Vorlage für eine “stehende Person”. Es analysiert Körperproportionen, Gliedmaßenwinkel und Bewegungsmuster. Eine kriechende Person hat immer noch ein Kopf-zu-Oberkörper-Verhältnis, eine Armlänge und eine Beinlänge, die der menschlichen Geometrie entsprechen. Die CNN wurde auf Datensätzen trainiert, die sitzende, hockende, gebückte und kriechende Körperhaltungen umfassen.
Nach meiner Erfahrung mit Integratoren für landwirtschaftliche Sicherheit kommt das Szenario des Kriechens häufiger vor, als man denkt. Eindringlinge versuchen oft, sich in der Nähe von Zäunen niedrig zu halten. Unser Algorithmus bewältigt dies, da er Skelett-Schlüsselpunkte extrahiert, auch wenn der Körper horizontal liegt. Das System bildet die Positionen der Gelenke ab und prüft, ob die Gesamtstruktur mit einem menschlichen Skelett übereinstimmt.
Die Rolle der Bewegungsanalyse
Statische Haltungsdetektion allein reicht nicht aus. Das System analysiert auch Bewegungsmuster. Eine kriechende Person bewegt sich anders als ein Hund oder eine rollende Staubflocke. Der Algorithmus betrachtet:
- Geschwindigkeit der Bewegung im Verhältnis zur Objektgröße
- Gliedmaßenartikulationsmuster (Arme und Beine bewegen sich in alternierenden Zyklen)
- Richtungsänderungen, die eine absichtliche Navigation anzeigen
Wann wird die Erkennung schwierig?
Es gibt Grenzfälle. Wenn eine Person zu einer engen Kugel zusammengerollt und völlig still ist, kann das System länger brauchen, um das Ziel zu klassifizieren. In diesen Situationen behält die Auto-Tracking-Logik der Kamera die PTZ-Position bei und wartet auf Bewegung, bevor sie den Alarm bestätigt. Dies verhindert falsch-negative Ergebnisse, ohne die 4G-Verbindung mit unsicheren Alarmen zu überfluten.
Leistung der Haltungsdetektion nach Entfernung
| Haltung | Zuverlässiger Erkennungsbereich | Mindestanforderung an Pixel | Konfidenzniveau |
|---|---|---|---|
| Stehen/Gehen | 20m – 100m | 32×64 Pixel | Hoch |
| Sitzen/Hocken | 10m – 60m | 48×48 Pixel | Hoch |
| Kriechen/Liegend | 5m – 40m | 64×32 Pixel | Mittel-Hoch |
| Gekrümmt/Stationär | 3m – 20m | 48×48 Pixel | Mittel |
Die wichtigste Erkenntnis hier ist, dass nicht standardmäßige Haltungen mehr Pixel im Bild benötigen. Deshalb ist der optische 40X7 Zoom wichtig. Das System erkennt ein potenzielles Ziel im Weitwinkelmodus und zoomt dann heran, um genügend Pixeldichte für die Haltungsklassifizierung zu erhalten.
Wie verbessert Re-ID für Fußgänger die Konsistenz der Verfolgung, wenn die Person die Richtung ändert?
Eine Person zu verfolgen, die geradeaus geht, ist einfach. Die eigentliche Herausforderung besteht darin, wenn sie sich umdreht, hinter einer Stange duckt oder ihre Kleidung durch Ausziehen einer Jacke wechselt. Standard-Bewegungsverfolgung verliert das Ziel in diesen Momenten.
Re-ID löst dies, indem es einen Merkmalsvektor aus dem Erscheinungsbild des Ziels extrahiert – Kleiderfarbe, Körperform, Accessoires und Gangart. Wenn die Person nach einer Verdeckung oder Richtungsänderung wieder erscheint, vergleicht das System die neue Erkennung mit gespeicherten Merkmalsvektoren. Wenn die Übereinstimmungspunktzahl über dem Schwellenwert liegt, wird die Verfolgung sofort fortgesetzt, ohne einen neuen Alarm auszulösen.
![]() Fußgänger Re-ID Verfolgung PTZ-Kamera Verdeckung
Fußgänger Re-ID Verfolgung PTZ-Kamera Verdeckung
Was passiert ohne Re-ID
Ohne Re-ID verwendet ein einfacher Tracker Positionsvorhersagen. Er rät, wo sich das Ziel im nächsten Bild basierend auf Geschwindigkeit und Richtung befinden wird. Wenn sich die Person um 180 Grad dreht, schlägt die Vorhersage fehl. Das System sieht dann ein “neues” Objekt, das sich in die entgegengesetzte Richtung bewegt. Dies verursacht zwei Probleme:
- Die PTZ-Kamera schwenkt möglicherweise in die falsche Richtung und verliert das Ziel vollständig.
- Das System generiert einen zweiten Alarm für dieselbe Person, was Bandbreite auf Ihrer 4G-Verbindung verschwendet.
Wie die Merkmalsvektor-Extraktion funktioniert
Der KI-Chip in unserer Kamera führt neben dem Erkennungsmodell ein leichtgewichtiges Embedding-Netzwerk aus. Für jedes bestätigte menschliche Ziel generiert es einen 128-dimensionalen oder 256-dimensionalen Merkmalsvektor. Betrachten Sie dies als einen numerischen Fingerabdruck des Erscheinungsbilds der Person.
Dieser Vektor kodiert:
- Dominante Farbblöcke (Hemdfarbe, Hosenfarbe)
- Texturmuster (Streifen, einfarbig, Warnweste)
- Körperproportionen (Größen-Breiten-Verhältnis, Schulterbreite)
- Getragene Gegenstände (Rucksack, Werkzeugkasten)
Der Abgleichprozess
Wenn die Verfolgung unterbrochen wird, speichert das System den letzten bekannten Feature-Vektor. Für die nächsten 30 bis 60 Sekunden (konfigurierbar) wird jede neue menschliche Erkennung im Bild mit diesem gespeicherten Vektor verglichen. Der Vergleich verwendet Kosinus-Ähnlichkeit1. Wenn der Wert 0,75 (einstellbar) überschreitet, verknüpft das System die neue Erkennung mit der bestehenden Verfolgung.
Re-ID-Einschränkungen, die Sie beachten sollten
Re-ID ist nicht perfekt. Es hat Schwierigkeiten, wenn:
- Mehrere Personen identische Uniformen tragen (häufig auf Baustellen)
- Die Beleuchtung zwischen Erkennung und Wiedererkennung dramatisch wechselt
- Die Person eine große äußere Kleidungsschicht aus- oder anzieht
Für Uniform-Szenarien empfehle ich die Aktivierung von Ganganalyse2 als ergänzende Funktion. Selbst wenn zwei Arbeiter dieselbe Weste tragen, unterscheiden sich ihre Gangmuster ausreichend, damit das System separate Spuren beibehalten kann.
Re-ID vs. Einfache Bewegungsverfolgung
| Merkmal | Einfache Bewegungsverfolgung | Re-ID-Verfolgung |
|---|---|---|
| Richtungswechsel bewältigen | Nein – Ziel verloren | Ja – Übereinstimmung anhand des Aussehens |
| Kurze Verdeckung bewältigen | Teilweise – maximal 1-2 Sekunden | Ja – bis zu 60 Sekunden |
| Mehrziel-Trennung | Schlecht — IDs wechseln häufig | Stark — eindeutige Vektoren pro Person |
| Rechenkosten | Sehr gering | Mäßig |
| Bester Anwendungsfall | Offenes Feld, einzelnes Ziel | Komplexe Standorte, mehrere Personen |
Löst die KI einen Alarm aus, wenn nur die Beine oder der Oberkörper einer Person im Bild sichtbar sind?
Dies geschieht häufiger, als man denkt. Eine Person hinter einer halben Mauer, einem Zaun oder abgestellten Maschinen zeigt möglicherweise nur teilweise Körperteile. Wenn Ihr System einen ganzen Körper benötigt, um auszulösen, haben Sie einen blinden Fleck.
Ja, das System löst bei teilweiser Sichtbarkeit des Körpers einen Alarm aus. Das Kopf-Schulter-Modell wurde speziell für Szenarien entwickelt, bei denen nur der Oberkörper sichtbar ist. Für Fälle, bei denen nur der Unterkörper sichtbar ist (Beine unter einer Barriere sichtbar), verwendet das Ganzkörpermodell die Erkennung von Gliedmaßenpaaren – die Erkennung von zwei Beinen mit menschlichen Gangmustern als ausreichenden Beweis, um das Ziel als Mensch zu klassifizieren.
 KI-Überwachungskamera mit Erkennung von Körperteilen
KI-Überwachungskamera mit Erkennung von Körperteilen
Wie die Erkennung von Körperteilen in der Praxis funktioniert
Die Erkennungspipeline führt mehrere Klassifikatoren parallel aus. Sie wartet nicht auf eine einzelne “Ganzkörper”-” Bounding Box4. Stattdessen sucht sie nach Körperteil-Clustern, die statistisch zu einem Menschen gehören.
Nur Oberkörper (Kopf, Schultern, Rumpf)
Dies ist der einfachere Fall. Das Kopf-Schulter-Modell wurde genau für dieses Szenario entwickelt. Die umgekehrte “U”-Form eines menschlichen Kopfes und seiner Schultern ist eine der markantesten Formen in der Natur. Kein gängiges Tier oder Objekt repliziert sie im gleichen Maßstab und Verhältnis.
Wenn nur der Oberkörper sichtbar ist:
- Das System führt zuerst den Kopf-Schulter-Klassifikator aus
- Wenn die Konfidenz 0,8 überschreitet, wird sofort ausgelöst
- Die PTZ versucht dann, zu zoomen oder zu schwenken, um mehr vom Ziel für eine sekundäre Bestätigung aufzudecken
Nur Unterkörper (Beine, Füße)
Dies ist schwieriger. Zwei vertikale Formen, die sich in alternierenden Mustern bewegen, könnten menschliche Beine sein, aber es könnten auch Zaunpfähle sein, die im Wind schwanken. Das System verwendet drei Prüfungen:
- Seitenverhältnis: Menschliche Beine haben ein bestimmtes Verhältnis von Breite zu Höhe, das sich von Stangen oder Pfosten unterscheidet.
- Artikulation: Beine biegen sich am Knie. Das System sucht nach periodischen Winkeländerungen an einem Mittelpunkt.
- Gangfrequenz: Menschliches Gehen hat eine Kadenz von etwa 1,5 bis 2,5 Schritten pro Sekunde. Das System prüft, ob die Bewegungshäufigkeit in diesem Bereich liegt.
Wenn alle drei Prüfungen bestanden sind, klassifiziert das System das Ziel als “wahrscheinlich menschlich” und löst einen Alarm mit geringer Zuverlässigkeit aus. Anschließend weist es die PTZ an, sich für einen besseren Winkel neu zu positionieren.
Nur Torso (Kein Kopf, Keine Beine)
Dies ist das herausforderndste Szenario für Teilerkennung. Ein Torso ohne Kopf oder Gliedmaßen könnte eine Person hinter einer Mauer sein, oder es könnte ein sich bewegendes Objekt wie ein Karren sein. In diesem Fall:
- Kennzeichnet das System die Erkennung als “unbestätigt”
- Hält die PTZ 3-5 Sekunden auf dem Ziel
- Wartet darauf, dass ein zusätzlicher Körperteil sichtbar wird
- Wenn keine zusätzlichen Beweise erscheinen, protokolliert es das Ereignis, sendet aber keinen 4G-Alarm
Dieser gestaffelte Ansatz hält Ihre Mobilfunkdatennutzung gering und erfasst dennoch potenzielle Bedrohungen.
Konfiguration der Empfindlichkeit für Ihren Standort
Für Standorte mit vielen Teilszenarien (Lagerhallen, umzäunte Anlagen) empfehle ich, den Mindestschwellenwert für die Zuverlässigkeit von 0,8 auf 0,65 zu senken und den Modus zur Erkennung von “Teilkörpern” in der Firmware zu aktivieren. Dies erhöht die Empfindlichkeit auf Kosten von etwas mehr zu überprüfenden Alarmen. Für Außenbereiche, in denen fast immer ganze Körper sichtbar sind, behalten Sie den Standard-Schwellenwert bei, um Rauschen zu minimieren.
Reduziert das Kopf-Schulter-Modell Fehlalarme, die durch große Tiere auf Bauernhöfen verursacht werden?
Farm-Installationen sind der schlimmste Fall für Fehlalarme. Hirsche, Kojoten, große Hunde und Nutztiere lösen alle eine grundlegende Bewegungserkennung aus. Wenn jede Tierdurchquerung um 3 Uhr morgens eine 4G-Push-Benachrichtigung auslöst, wird Ihr Kunde das System innerhalb einer Woche deaktivieren.
Ja, das Kopf-und-Schulter-Modell reduziert Tier-verursachte Fehlalarme drastisch. Der Hauptunterschied ist die Skelettgeometrie: Menschen haben horizontale Schultern senkrecht zu einem vertikalen Hals, die eine umgekehrte “U”-Form bilden. Kein vierbeiniges Tier repliziert diese Struktur. Selbst große Tiere wie Hirsche oder Pferde haben eine schräge Nacken-Rücken-Linie, die das Modell explizit herausfiltert.
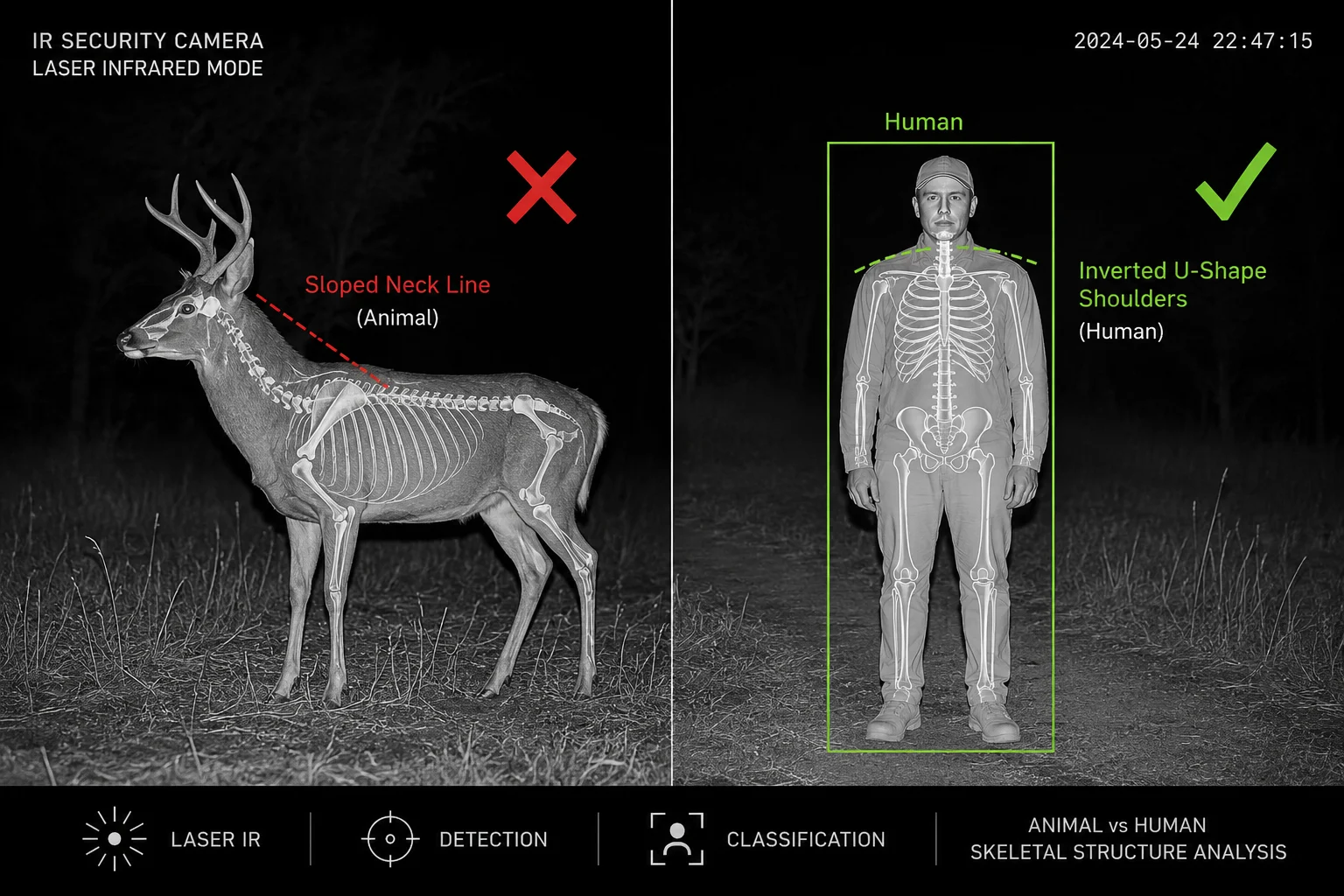 Überwachungskamera-Fehlalarm-Tierfilter für Bauernhöfe
Überwachungskamera-Fehlalarm-Tierfilter für Bauernhöfe
Warum Tiere einfache Erkennung täuschen
Grundlegende Bewegungserkennung und sogar einige Low-End-“Personenerkennungssysteme” verwenden die einfache Größe von Begrenzungsrahmen als primären Filter. Ein großes Reh in 30 Metern Entfernung erzeugt einen Begrenzungsrahmen, der in der Größe einem Menschen in 50 Metern Entfernung ähnelt. Ohne Formanalyse kann das System sie nicht unterscheiden.
Einige Budget-Kameras verwenden einen einstufigen Detektor, der nur prüft: “Ist dieses Objekt groß genug und bewegt es sich?” Dieser Ansatz scheitert auf Bauernhöfen und ländlichen Standorten vollständig.
Wie unser mehrschichtiger Ansatz dies löst
Die Erkennungspipeline für den Farmmodus funktioniert wie folgt:
- Bewegungsauslöser: Etwas bewegt sich im Bild. Das System wacht auf.
- Ganzkörper-Vorfilter: Sind das Seitenverhältnis und die Bewegungsgeschwindigkeit des Objekts mit denen eines Menschen vereinbar? Wenn ja, fortfahren. Wenn sich das Objekt auf vier Beinen bewegt oder eine horizontale Körperachse hat, wird es als “Tier” markiert und unterdrückt.
- Kopf-Schulter-Bestätigung: Zeigt der obere Teil des Objekts das umgekehrte “U”-Muster? Dies ist die entscheidende Prüfung.
- Größenvalidierung: Liegt die Pixelgröße des Objekts im erwarteten Bereich für einen Menschen in dieser Entfernung? (Verwendung der bekannten Brennweite und des Neigungswinkels der Kamera zur Entfernungsschätzung.)
Strukturelle Unterschiede zwischen Tier und Mensch
Das Kopf-Schulter-Modell nutzt grundlegende anatomische Unterschiede:
- Menschen: Vertikaler Hals, horizontale Schulterlinie, Kopf zentriert über den Schultern
- Rehe/Pferde: Hals erstreckt sich um 45-60 Grad nach vorne, keine horizontale Schulterlinie
- Hunde/Kojoten: Kopf ist vor dem Körperzentrum, Schulterbreite ist im Verhältnis zur Körperlänge schmal
- Bären (stehend): Am nächsten zur menschlichen Form, aber das Verhältnis von Schulter zu Kopf und die Armposition unterscheiden sich erheblich
Reduzierung von Fehlalarmen in der realen Welt
Basierend auf Felddaten von Farminstallationen in Texas und Alberta reduziert die Aktivierung des Kopf-Schulter-Filters tierbedingte Fehlalarme um 85-95%. Die verbleibenden 5-15% der Fehlalarme stammen typischerweise von:
- Aufrecht stehende Bären (selten, aber möglich)
- Große Vögel, die auf Zaunpfähle in unmittelbarer Nähe landen (Silhouette ähnelt kurzzeitig einem Kopf)
- Vogelscheuchen oder Schaufensterpuppen (diese werden korrekt als “menschenähnlich” erkannt – das System kann nicht wissen, dass sie nicht echt sind)
Empfohlene Farmkonfiguration
| Einstellung | Empfohlener Wert | Grund |
|---|---|---|
| Erkennungsmodus | Kopf-Schulter-Priorität | Filtert Vierbeiner effektiv |
| Minimale Pixelgröße | 40×40 | Ignoriert Kleintiere (Kaninchen, Vögel) |
| Bewegungsempfindlichkeit | Mittel | Reduziert Auslöser durch Wind/Vegetation |
| Alarm-Cooldown | 30 Sekunden | Verhindert wiederholte Alarme vom selben Tier |
| Nachtmodus | Laser-IR + thermische Unterstützung | Behält die Klarheit der Form in Dunkelheit bei |
Für Bauernhofprojekte empfehle ich außerdem, das Flag “Tierunterdrückung” in der Firmware zu setzen. Dies erhöht die Verarbeitungszeit pro Erkennung um 200 ms, reduziert aber das Volumen von Fehlalarmen um eine Größenordnung. Bei einer 4G-Verbindung, bei der jede Benachrichtigung Bandbreite und Akku kostet, lohnt sich dieser Kompromiss jedes Mal.
Schlussfolgerung
Personenerkennung in unserem PTZ-Kameras6 ist kein einzelner Algorithmus – es ist ein geschichtetes System. Die Ganzkörpererkennung deckt große Entfernungen ab. Die Kopf-Schulter-Filterung eliminiert Fehlalarme. Re-ID sorgt für die Verfolgung bei Verdeckungen. Zusammen liefern sie zuverlässige Leistung für Projekte in den Bereichen Landwirtschaft, Bauwesen und Perimetersicherheit.
1. Definition und Verwendung der Kosinus-Ähnlichkeit zum Vergleichen von Merkmalsvektoren bei Abruf und Abgleich. ︎↩︎ 2. Erfahren Sie, wie Gangmuster als Biometrie zur Personenidentifizierung verwendet werden. ︎↩︎ 3. Verständnis des Seitenverhältnisses in der Bildverarbeitung für Objekterkennung und -klassifizierung. ︎↩︎ 4. Konzept von Bounding Boxes, die bei der Objekterkennung verwendet werden, um Objekte in einem Bild zu lokalisieren. ︎↩︎ 5. Allgemeine Definition von Fehlalarmen und deren Auswirkungen auf die Zuverlässigkeit von Sicherheitssystemen. ︎↩︎ 6. Einführung in Schwenk-Neige-Zoom-Kameras und ihre Anwendungen in der Überwachung. ︎↩︎ 7. Erklärung von optischem Zoom im Vergleich zu digitalem Zoom in Bildgeräten. ︎↩︎ 8. Verstehen Sie die Grundlagen der Ganzkörper-Personenerkennung in der Computer Vision. ︎↩︎