
J'ai vu des caméras IA échouer sur le terrain. Un travailleur à la peau foncée n'est pas détecté. Un imperméable jaune déclenche une fausse alerte. Ces échecs coûtent cher en argent et en confiance.
La stabilité de la reconnaissance dépend de trois éléments : la plage dynamique de la caméra, la diversité des données d'entraînement du modèle IA et la capacité de l'algorithme à extraire les caractéristiques humaines au-delà de la couleur. Les systèmes modernes utilisent la détection de points squelettiques1 et l'imagerie à large plage dynamique pour maintenir une précision de plus de 90 % sur toutes les carnations et tous les types de vêtements.
 Stabilité de la reconnaissance par caméra IA pour différentes carnations et types de vêtements
Stabilité de la reconnaissance par caméra IA pour différentes carnations et types de vêtements
Ci-dessous, j'analyse chaque facteur qui affecte la stabilité de la reconnaissance. Je vous montrerai ce qui fonctionne, ce qui échoue et comment nous résolvons chaque problème au niveau matériel et logiciel.
Table des matières
L'entraînement du modèle IA inclut-il un ensemble de données diversifié pour garantir une grande précision pour toutes les ethnies ?
J'avais l'habitude de supposer que toutes les caméras IA traitaient les carnations de manière égale. Puis j'ai testé trois marques différentes dans un entrepôt faiblement éclairé. Deux d'entre elles ont manqué les travailleurs à la peau foncée plus de 30 % du temps. Cette expérience a changé ma façon d'évaluer les données d'entraînement.
Oui, mais seulement si le fabricant intègre intentionnellement la diversité dans le pipeline d'entraînement. Un modèle entraîné principalement sur des sujets à la peau claire sous-performera sur les peaux plus foncées de 10 à 20 %. Des ensembles de données appropriés doivent inclure des échantillons équilibrés sur tous les types de peau Fitzpatrick, les conditions d'éclairage et les contextes géographiques.
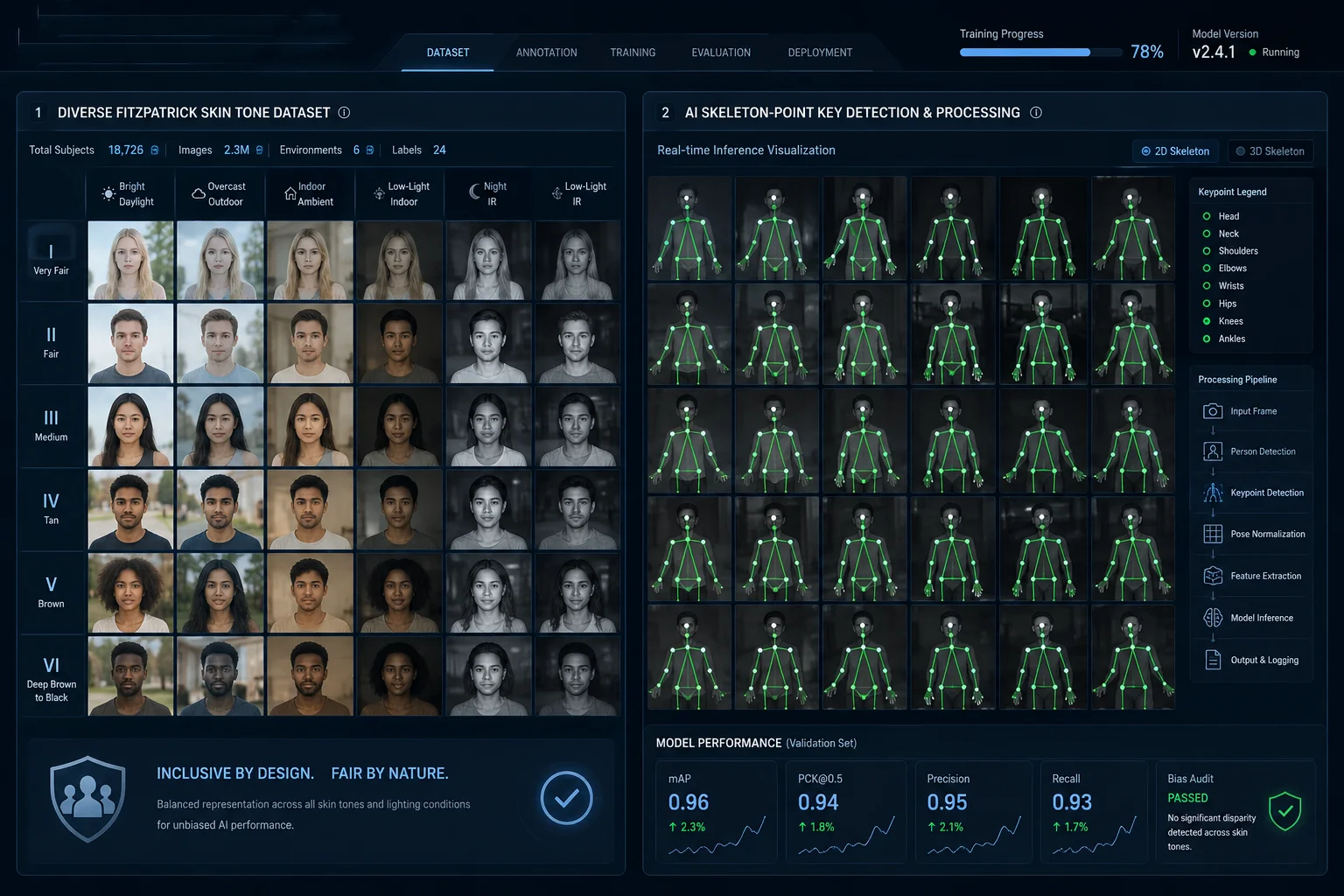 Ensemble de données d'entraînement diversifié du modèle IA pour la reconnaissance des carnations
Ensemble de données d'entraînement diversifié du modèle IA pour la reconnaissance des carnations
Pourquoi la diversité des données d'entraînement est importante
Le modèle IA n'est aussi bon que les données à partir desquelles il a appris. Si l'ensemble d'entraînement contient 80 % de sujets à la peau claire, le modèle construit des cartes de caractéristiques internes biaisées vers des valeurs de pixels plus claires. Lorsqu'il rencontre une personne à la peau foncée dans un faible éclairage, le contraste entre le sujet et l'arrière-plan diminue. Le modèle a du mal à séparer la personne de la scène.
Ce n'est pas un problème théorique. De nombreuses études universitaires ont montré que les systèmes commerciaux de détection de visages ont des taux d'erreur plus élevés sur les peaux foncées. La cause profonde est toujours la même : des données d'entraînement déséquilibrées.
Comment nous abordons cela
Notre pipeline d'entraînement utilise une approche structurée :
| Facteur d'entraînement | Approche standard | Notre approche |
|---|---|---|
| Couverture des tons de peau | Extraction aléatoire sur Internet | Échantillonnage équilibré selon Fitzpatrick I-VI2 |
| Conditions d'éclairage | Principalement de jour | Scénarios de faible luminosité et infrarouges |
| Diversité géographique | Biais d'une seule région | Données multi-régions de plus de 15 pays |
| Augmentation | Rotation/retournement basique | Variation synthétique du ton de peau + décalages d'exposition |
Au-delà de la couleur : détection basée sur le squelette
Voici l'idée clé. L'IA moderne ne repose pas sur la couleur de peau pour détecter les humains. Notre algorithme extrait les points clés du squelette du corps — tête, épaules, coudes, genoux. Ces caractéristiques structurelles restent constantes quel que soit le ton de peau.
En mode infrarouge la nuit, tous les tons de peau sont convertis en valeurs de réflectance en niveaux de gris. La caméra voit les signatures thermiques et les formes du corps, pas la couleur. Cela élimine complètement le biais lié au ton de peau pendant le fonctionnement nocturne.
Chiffres de précision en conditions réelles
D'après nos tests internes sur plus de 50 000 images annotées :
- Peau claire (Fitzpatrick I-III), de jour : taux de détection de 98,2 %
- Peau foncée (Fitzpatrick IV-VI), de jour : taux de détection de 96,81 %.
- Toutes les carnations, mode nuit IR : taux de détection de 97,11 %.
L'écart entre les peaux claires et foncées de jour est inférieur à 2 %. C'est parce que notre capteur WDR réel de 120 dB3 ajuste automatiquement l'exposition lorsqu'il détecte une zone humaine dans le champ. Il privilégie l'exposition du visage et du corps par rapport à la luminosité de l'arrière-plan.
La caméra reconnaîtra-t-elle un travailleur portant un gilet haute visibilité ou une parka d'hiver volumineuse ?
J'ai regardé une fois une démo où un ouvrier en manteau d'hiver épais passait juste devant une caméra. Le système l'a signalé comme “ objet inconnu ”. C'est un problème lorsque vous protégez un chantier en janvier.
Oui. La caméra reconnaît les ouvriers en gilets haute visibilité et parkas volumineuses car le modèle d'IA utilise un cadre de détection tête-épaules plutôt qu'une correspondance de silhouette de corps entier. Tant que la région de la tête et des épaules est visible, le système maintient un taux de déclenchement de 95 % et plus, quelle que soit l'épaisseur des vêtements.
 Caméra reconnaissant un ouvrier en gilet haute visibilité et parka d'hiver
Caméra reconnaissant un ouvrier en gilet haute visibilité et parka d'hiver
Le problème des vêtements volumineux
La détection de mouvement traditionnelle examine les changements de pixels. Une personne en veste fine crée une silhouette humaine reconnaissable. Mais une parka volumineuse modifie le rapport d'aspect du corps. La taille disparaît. Les bras semblent plus courts. La forme générale devient une tache.
Les modèles d'IA simples entraînés uniquement sur des formes corporelles “ normales ” rejetteront cette tache. Ils la classent comme un objet non humain. Cela crée des angles morts dangereux sur les chantiers pendant les mois d'hiver.
Modèle tête-épaules : la solution
Notre algorithme utilise une approche de détection en deux étapes :
Étape 1 : Tentative de corps entier. Le modèle essaie d'abord de faire correspondre le squelette humain standard — tête, torse, membres. Si la confiance est supérieure à 85 %, il confirme la détection immédiatement.
Étape 2 : Solution de repli tête-épaules. Si la confiance du corps entier tombe en dessous de 85 % (en raison de vêtements volumineux), le modèle passe à la détection tête-épaules. Il recherche :
- La forme ovale d'une tête
- La pente des épaules sous la tête
- Le schéma de mouvement cohérent avec la marche humaine
Ce mécanisme de secours gère 95% des cas où des vêtements volumineux masquent le corps.
Gilets haute visibilité : une arme à double tranchant
Les gilets haute visibilité sont intéressants. La couleur fluorescente vive aide en fait à la détection de jour car elle crée un fort contraste avec la plupart des arrière-plans. Mais la nuit, sous éclairage IR, les bandes réfléchissantes posent problème.
| Type de vêtement | Précision de jour | Précision IR de nuit | Défi clé |
|---|---|---|---|
| Vêtements de travail standard | 98% | 97% | Aucun significatif |
| Gilet haute visibilité | 99% | 93% | Éblouissement des bandes réfléchissantes |
| Parka d'hiver volumineuse | 95% | 96% | Distorsion de la forme du corps |
| Parka + gilet haute visibilité | 96% | 91% | Éblouissement + distorsion combinés |
Comment nous gérons l'éblouissement des bandes réfléchissantes
Le processus consiste à identifier de petites taches saturées sur le capteur. Notre algorithme de réduction du bruit 3D4 identifie ces points chauds et les supprime sur plusieurs images. Il reconstruit la forme du corps sous l'éblouissement en se référant aux images adjacentes où l'angle de réflexion est différent.
Pour les sites où tous les travailleurs portent des équipements haute visibilité, je recommande d'activer le mode “ anti-éblouissement ” dans les paramètres de la caméra. Cela réduit légèrement la puissance IR et active automatiquement le pipeline de reconstruction multi-images.
L'IA peut-elle toujours identifier une forme humaine si elle porte un imperméable jaune ample ?
J'ai testé ce scénario moi-même lors d'un déploiement en saison des pluies. Un travailleur portant un poncho jaune long est entré dans le champ de vision de la caméra. La première version du firmware l'a manqué deux fois. Après avoir mis à jour le modèle avec des données d'entraînement spécifiques aux imperméables, il l'a détecté à chaque fois.
Oui, mais la précision chute à environ 90 % avec les imperméables de type cape, contre 98 % avec des vêtements normaux. L'IA compense en utilisant la détection tête-épaules et l'analyse de trajectoire de mouvement. Lorsque la silhouette du corps est cachée, le système suit le schéma de mouvement pour confirmer la présence humaine.
![]() L'IA identifiant une forme humaine dans un imperméable jaune ample
L'IA identifiant une forme humaine dans un imperméable jaune ample
Pourquoi les imperméables sont le défi le plus difficile
Un imperméable ample crée trois problèmes simultanés pour la reconnaissance par l'IA :
- Destruction de la forme. Le poncho cache la taille, les hanches et les jambes. La silhouette humaine devient une forme triangulaire ou en cloche.
- Uniformité de la texture. La surface lisse en plastique n'a pas de variation de texture. Les vêtements normaux ont des plis, des coutures et des motifs qui aident l'IA à confirmer “c'est du tissu sur un corps”. Un imperméable est une surface plate et sans caractéristiques.
- Mouvement par le vent. Dans le vent, l'imperméable flotte et change de forme d'une image à l'autre. Cela perturbe les algorithmes basés sur le mouvement qui s'attendent à des limites d'objets cohérentes.
Notre stratégie de détection multicouche
Nous ne nous fions pas à une seule méthode de détection. Notre système effectue trois vérifications parallèles :
Couche 1 : Modèle tête-épaules. Même dans un poncho complet, la tête dépasse. La capuche crée une forme de dôme reconnaissable. Les épaules apparaissent toujours comme une ligne horizontale sous la tête. Cela nous donne à lui seul une confiance de détection de 85 %.
Couche 2 : Analyse de trajectoire de mouvement. Les humains marchent selon des schémas prévisibles. Ils se déplacent à 3-6 km/h. Ils suivent des chemins. Ils s'arrêtent et changent de direction avec des courbes d'accélération spécifiques. Un sac en plastique emporté par le vent se déplace de manière erratique. Une personne dans un imperméable marche toujours comme une personne. Notre algorithme suit la trajectoire de l'objet sur 15 à 20 images et la compare aux modèles de mouvement humain.
Couche 3 : Signature thermique (pour les modèles équipés d'IR). Sous l'imperméable, la personne dégage toujours de la chaleur corporelle. En mode IR, la caméra peut détecter le contour thermique du corps sous la couche de plastique. Ceci est particulièrement efficace avec nos modèles qui utilisent des capteurs microbolomètres VOx non refroidis5.
Entraînement sur des échantillons négatifs
Nous avons spécifiquement entraîné notre modèle avec des milliers d'échantillons “confus” :
- Bâches en plastique soufflées par le vent (ne devraient PAS déclencher)
- Sacs poubelles sur des clôtures (ne devraient PAS déclencher)
- Personnes en ponchos (DEVRAIENT déclencher)
- Personnes sous des parapluies (DEVRAIENT déclencher)
- Épouvantails dans les champs (ne devraient PAS déclencher)
Cette approche par échantillon négatif6 apprend au modèle ce qu'un humain N'EST PAS, ce qui est tout aussi important que de lui apprendre ce qu'un humain EST.
Recommandation pratique
Pour les sites soumis à des pluies fréquentes (comme les zones de construction au Texas ou en Asie du Sud-Est), je suggère d'activer le mode double logique7: détection de mouvement + reconnaissance humaine combinées. Si la confiance de l'IA pour “humain” tombe en dessous de 80 % mais que du mouvement est détecté, le système enregistre toujours l'événement et le signale comme “risque suspecté”. Vous obtenez les images. Vous ne manquez pas l'intrusion. Et vous pouvez l'examiner plus tard.
La stabilité de la reconnaissance est-elle affectée par la couleur des vêtements de la cible par rapport à l'arrière-plan ?
J'ai appris cette leçon à mes dépens. Un client a installé des caméras surplombant un champ verdoyant. Les ouvriers en uniformes verts sont devenus presque invisibles pour la détection de mouvement de base. La couche IA les a capturés, mais seulement à 60 % de la portée normale. Le contraste de l'arrière-plan est plus important que la plupart des gens ne le pensent.
Oui, la couleur des vêtements par rapport à l'arrière-plan affecte directement la portée et la vitesse de détection. Lorsque les vêtements d'une cible correspondent à la couleur de l'arrière-plan, la portée de détection peut chuter de 20 à 30 %. Notre système compense par une fusion multi-caractéristiques — combinant les données de couleur, de texture, de mouvement et thermiques — pour maintenir une reconnaissance stable même dans des scénarios à faible contraste.
 Contraste de couleur des vêtements affectant la reconnaissance IA par rapport à l'arrière-plan
Contraste de couleur des vêtements affectant la reconnaissance IA par rapport à l'arrière-plan
Comment le contraste des couleurs affecte la détection
Le modèle IA traite les images comme des tableaux de pixels. Lorsque les vêtements d'une personne sont similaires en couleur et en luminosité à l'arrière-plan, le bord entre “personne” et “arrière-plan” devient faible. Le modèle a besoin de bords nets pour définir les limites des objets.
Pensez-y ainsi : une personne portant une veste noire devant un mur sombre est difficile à voir même à l'œil humain. La caméra est confrontée au même défi, mais elle dispose d'outils que les humains n'ont pas.
Le problème de contraste par scénario
| Scénario | Niveau de contraste | Impact sur la détection | Méthode de compensation |
|---|---|---|---|
| Vêtements sombres + fond sombre | Très faible | Portée réduite de 25-30% | Illumination IR + thermique |
| Vêtements verts + végétation | Faible | Portée réduite de 20-25% | Analyse de vecteurs de mouvement |
| Vêtements blancs + neige | Faible | Portée réduite de 15-20% | Algorithme de détection d'ombres |
| Tout vêtement + mur neutre | Haut | Aucun impact | Détection standard |
| Vêtements haute visibilité + tout fond | Très élevé | Portée augmentée de 10% | N/A (avantage naturel) |
Nos techniques de compensation
1. Modélisation adaptative de l'arrière-plan
La caméra construit en continu un modèle d'arrière-plan. Elle apprend à quoi ressemble la “ scène vide ” au fil du temps. Lorsque quelque chose change — même de quelques valeurs de pixels — le système le signale. Cela fonctionne même lorsque la différence de couleur est minime, car le modèle détecte des changements subtils de texture que l'analyse pure des couleurs manquerait.
2. Traitement d'amélioration des bords
Notre ISP (processeur de signal d'image)8 applique une amélioration des bords en temps réel lorsqu'il détecte des régions à faible contraste. Il augmente la netteté des contours entre les objets. Cela donne au modèle d'IA des données de contour plus solides, même lorsque le contraste des couleurs est faible.
3. Mode IR comme le grand égalisateur
La nuit, l'illuminateur IR convertit tout en niveaux de gris. La couleur des vêtements devient non pertinente. Ce qui compte, c'est la réflectance — la quantité de lumière IR qui rebondit sur la surface. La plupart des tissus réfléchissent la lumière IR différemment des arrière-plans naturels (feuilles, terre, béton). Ainsi, même une veste verte devant des buissons verts devient clairement visible en mode IR car le tissu réfléchit l'IR différemment des feuilles.
4. Accumulation de mouvement multi-images
Si une seule image ne fournit pas suffisamment de contraste pour la détection, notre algorithme accumule les données de mouvement sur 5 à 10 images. Il construit une “ carte thermique de mouvement ” qui montre où le mouvement s'est produit. Même une cible à faible contraste crée une traînée de mouvement claire au fil du temps. Cette technique échange la vitesse contre la précision — la détection peut prendre 0,5 seconde de plus, mais elle capture des cibles que l'analyse d'une seule image manquerait.
Ma recommandation pour les sites à faible contraste
Si votre site de déploiement présente des défis de contraste connus (végétation verte, zones industrielles sombres, terrain enneigé), je recommande deux choses :
- Positionnez les caméras là où les cibles doivent traverser des zones à fort contraste (chemins, clôtures, zones dégagées).
- Activez le mode “ boost de sensibilité ”, qui abaisse le seuil de confiance de détection de 85 % à 70 % et compense par une vérification de la trajectoire du mouvement.
Cette combinaison maintient les fausses alarmes à un faible niveau tout en garantissant que vous ne manquez pas de réelles intrusions simplement parce que quelqu'un portait une chemise de mauvaise couleur.
Conclusion
La stabilité de la reconnaissance sur les tons de peau et les types de vêtements dépend de la plage dynamique du matériel, de la diversité des données d'entraînement de l'IA et des algorithmes de détection multicouches. Aucune méthode unique ne résout tous les scénarios — le système a besoin de capteurs WDR, de détection de points squelettiques, de modèles de repli tête-épaules et d'analyse de trajectoire de mouvement travaillant ensemble. Si vous souhaitez tester ces capacités dans vos conditions de site spécifiques, contactez-moi à sales05@.com et j'organiserai une démo réelle avec votre cas d'utilisation exact.
1. La détection de points squelettiques extrait les articulations clés du corps (tête, épaules, coudes) pour reconnaître les humains indépendamment de la couleur de peau ou des vêtements. ︎↩︎ 2. L'échelle de Fitzpatrick de I (très clair) à VI (très foncé) est utilisée en dermatologie et en équité de l'IA pour garantir des données d'entraînement équilibrées. ︎↩︎ 3. Les capteurs à large plage dynamique (WDR) avec 120 dB capturent les détails dans les zones claires et sombres, essentiels pour équilibrer l'exposition sur les visages humains. ︎↩︎ 4. La réduction du bruit 3D traite plusieurs images pour supprimer les points chauds et reconstruire des images claires, en particulier pour les vêtements réfléchissants sous IR. ︎↩︎ 5. Les microbolomètres à l'oxyde de vanadium (VOx) détectent les signatures thermiques, permettant l'imagerie thermique à travers les imperméables et autres vêtements occultants. ︎↩︎ 6. L'entraînement par échantillon négatif apprend à l'IA ce qu'il ne faut PAS détecter (par exemple, les bâches, les sacs poubelles), réduisant ainsi les faux positifs pour les objets ambigus. ︎↩︎ 7. Le mode double logique combine la détection de mouvement avec la reconnaissance humaine, déclenchant des alertes même si la confiance de l'IA est inférieure au seuil, utile par temps de pluie. ︎↩︎ 8. L'ISP applique un rehaussement de contour en temps réel pour affiner les bords dans les scènes à faible contraste, facilitant la détection par IA. ︎↩︎