
Ich habe gesehen, wie KI-Kameras im Einsatz versagten. Ein dunkelhäutiger Arbeiter wird nicht erkannt. Ein gelber Regenmantel löst einen Fehlalarm aus. Diese Fehler kosten echtes Geld und echtes Vertrauen.
Die Erkennungsstabilität hängt von drei Dingen ab: dem Dynamikbereich der Kamera, der Vielfalt der Trainingsdaten des KI-Modells und der Fähigkeit des Algorithmus, menschliche Merkmale jenseits von Farbe zu extrahieren. Moderne Systeme verwenden Skelettpunkt-Erkennung1 und Wide-Dynamic-Range-Imaging, um eine Genauigkeit von über 90 % über alle Hauttöne und Kleidungsarten hinweg aufrechtzuerhalten.
 KI-Kamera-Erkennungsstabilität für verschiedene Hauttöne und Kleidungsarten
KI-Kamera-Erkennungsstabilität für verschiedene Hauttöne und Kleidungsarten
Unten erläutere ich jeden Faktor, der die Erkennungsstabilität beeinflusst. Ich zeige Ihnen, was funktioniert, was fehlschlägt und wie wir jedes Problem auf Hardware- und Softwareebene lösen.
Inhaltsübersicht
Beinhaltet das KI-Modelltraining einen vielfältigen Datensatz, um eine hohe Genauigkeit für alle Ethnien zu gewährleisten?
Früher ging ich davon aus, dass alle KI-Kameras Hauttöne gleich behandeln. Dann testete ich drei verschiedene Marken in einem schlecht beleuchteten Lagerhaus. Zwei davon erfassten dunkelhäutige Arbeiter über 30 % der Zeit nicht. Diese Erfahrung änderte meine Bewertung von Trainingsdaten.
Ja, aber nur, wenn der Hersteller bewusst Vielfalt in die Trainingspipeline integriert. Ein Modell, das hauptsächlich auf hellhäutigen Personen trainiert wurde, wird bei dunkleren Hauttönen um 10-20 % schlechter abschneiden. Geeignete Datensätze müssen ausgewogene Stichproben über alle Fitzpatrick-Hauttypen, Lichtverhältnisse und geografischen Kontexte enthalten.
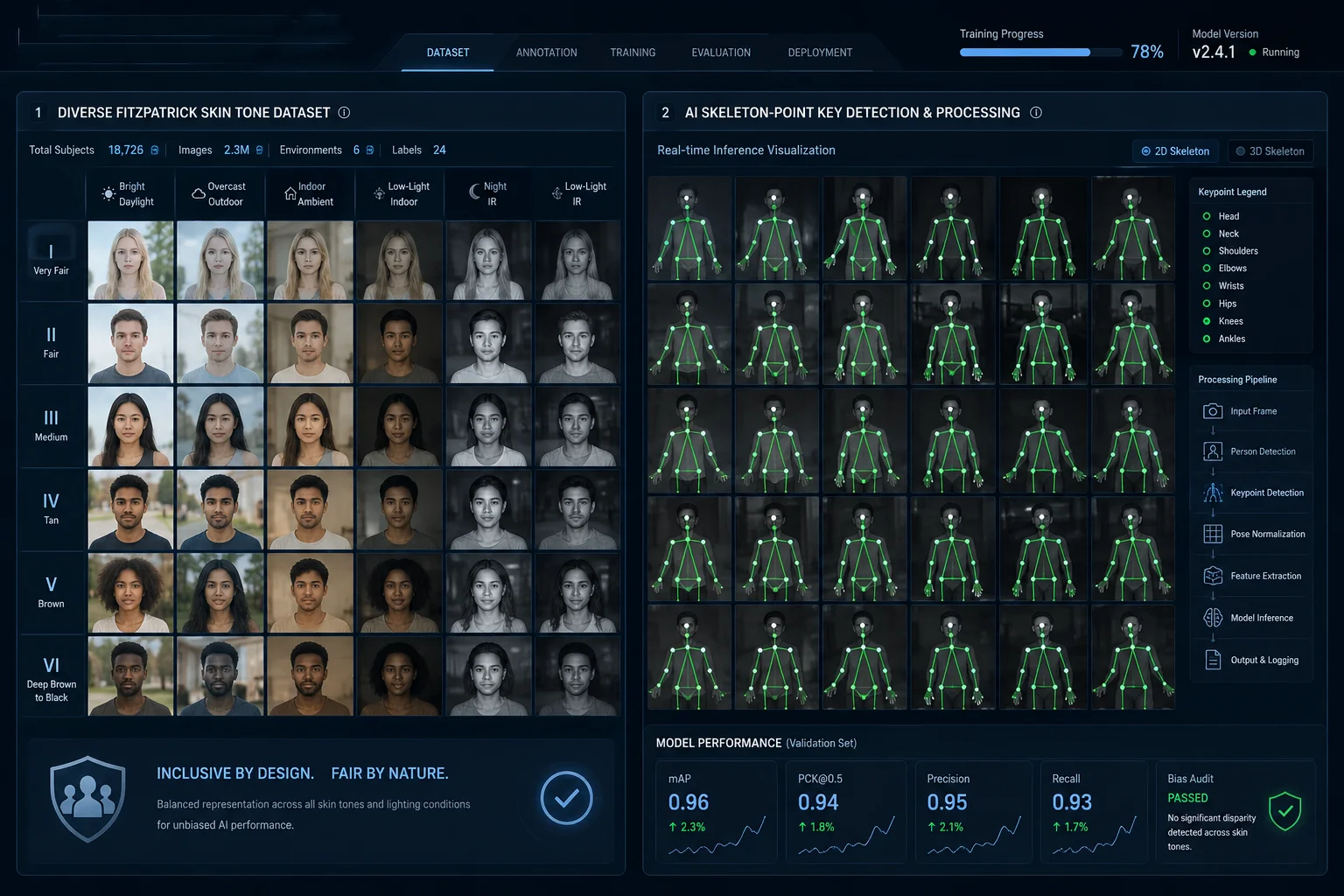 KI-Modell-vielfältiger Trainingsdatensatz für Hauttonerkennung
KI-Modell-vielfältiger Trainingsdatensatz für Hauttonerkennung
Warum Trainingsdatenvielfalt wichtig ist
Das KI-Modell ist nur so gut wie die Daten, von denen es gelernt hat. Wenn der Trainingsdatensatz zu 80 % aus hellhäutigen Personen besteht, erstellt das Modell interne Merkmalskarten, die auf hellere Pixelwerte voreingenommen sind. Wenn es auf eine dunkelhäutige Person bei schlechten Lichtverhältnissen trifft, sinkt der Kontrast zwischen dem Motiv und dem Hintergrund. Das Modell hat Schwierigkeiten, die Person von der Szene zu trennen.
Dies ist kein theoretisches Problem. Mehrere wissenschaftliche Studien haben gezeigt, dass kommerzielle Gesichtserkennungssysteme bei dunkleren Hauttönen höhere Fehlerraten aufweisen. Die Grundursache ist immer dieselbe: unausgewogene Trainingsdaten.
Wie wir das angehen
Unsere Trainingspipeline verwendet einen strukturierten Ansatz:
| Trainingsfaktor | Standardansatz | Unser Ansatz |
|---|---|---|
| Hauttonabdeckung | Zufälliges Internet-Scraping | Ausgewogene Stichproben über Fitzpatrick I-VI2 |
| Lichtverhältnisse | Hauptsächlich tagsüber | 40% Schwachlicht- und IR-Szenarien |
| Geografische Vielfalt | Einzige regionale Voreingenommenheit | Multiregionale Daten aus über 15 Ländern |
| Augmentierung | Einfache Drehung/Spiegelung | Synthetische Hauttonvariation + Belichtungsverschiebungen |
Jenseits der Farbe: Skelettbasierte Erkennung
Hier ist die wichtigste Erkenntnis. Moderne KI verlässt sich nicht auf Hautfarbe, um Menschen zu erkennen. Unser Algorithmus extrahiert Skelett-Schlüsselpunkte des Körpers – Kopf, Schultern, Ellbogen, Knie. Diese strukturellen Merkmale bleiben unabhängig vom Hautton konstant.
Im Infrarotmodus bei Nacht werden alle Hauttöne in Graustufen-Reflexionswerte umgewandelt. Die Kamera sieht Wärmesignaturen und Körperformen, nicht Farbe. Dies eliminiert Hautton-Voreingenommenheit während des Nachtbetriebs vollständig.
Echte Genauigkeitszahlen
Aus unseren internen Tests mit über 50.000 annotierten Frames:
- Helle Haut (Fitzpatrick I-III), tagsüber: 98,2% Erkennungsrate
- Dunkle Haut (Fitzpatrick IV-VI), tagsüber: 96,8% Erkennungsrate
- Alle Hauttöne, IR-Nachtmodus: 97,1% Erkennungsrate
Die Lücke zwischen heller und dunkler Haut am Tag liegt unter 2%. Dies liegt daran, dass unser 120-dB-True-WDR-Sensor3 die Belichtung automatisch anpasst, wenn er einen menschlichen Bereich im Bild erkennt. Er priorisiert die Belichtung von Gesicht und Körper gegenüber der Helligkeit des Hintergrunds.
Erkennt die Kamera einen Arbeiter, der eine Warnweste oder einen dicken Winterparka trägt?
Ich habe einmal eine Demo gesehen, bei der ein Arbeiter in einem dicken Wintermantel direkt an einer Kamera vorbeiging. Das System kennzeichnete ihn als “unbekanntes Objekt”. Das ist ein Problem, wenn man im Januar eine Baustelle schützt.
Ja. Die Kamera erkennt Arbeiter in Warnwesten und dicken Parkas, da das KI-Modell ein Kopf-Schulter-Erkennungs-Framework verwendet und nicht die Silhouette des gesamten Körpers abgleicht. Solange der Kopf- und Schulterbereich sichtbar ist, behält das System eine Auslöserate von 95%+ bei, unabhängig von der Kleidung.
 Kamera erkennt Arbeiter in Warnweste und Winterparka
Kamera erkennt Arbeiter in Warnweste und Winterparka
Das Problem mit dicker Kleidung
Die herkömmliche Bewegungserkennung betrachtet Pixeländerungen. Eine Person in einer schlanken Jacke erzeugt eine erkennbare menschliche Silhouette. Aber ein dicker Parka verändert das Seitenverhältnis des Körpers. Die Taille verschwindet. Die Arme wirken kürzer. Die Gesamtform wird zu einem Klumpen.
Einfache KI-Modelle, die nur auf “normalen” Körperformen trainiert wurden, lehnen diesen Klumpen ab. Sie klassifizieren ihn als nicht-menschliches Objekt. Dies schafft gefährliche blinde Flecken auf Baustellen während der Wintermonate.
Kopf-Schulter-Modell: Die Lösung
Unser Algorithmus verwendet einen zweistufigen Erkennungsansatz:
Stufe 1: Versuch der Ganzkörpererkennung. Das Modell versucht zunächst, das Standard-Skelett eines Menschen abzugleichen – Kopf, Rumpf, Gliedmaßen. Wenn die Konfidenz über 85% liegt, wird die Erkennung sofort bestätigt.
Stufe 2: Kopf-Schulter-Fallback. Wenn die Konfidenz für den Ganzkörper unter 85% fällt (aufgrund dicker Kleidung), schaltet das Modell auf Kopf-Schulter-Erkennung um. Es sucht nach:
- Der ovalen Form eines Kopfes
- Der Neigung der Schultern unterhalb des Kopfes
- Dem Bewegungsmuster, das mit menschlichem Gehen übereinstimmt
Dieser Fallback erfasst 95% der Fälle, in denen sperrige Kleidung den Körper verdeckt.
Warnwesten: Ein zweischneidiges Schwert
Warnwesten sind interessant. Die leuchtende fluoreszierende Farbe hilft tatsächlich bei der Erkennung am Tag, da sie einen starken Kontrast zu den meisten Hintergründen bildet. Aber nachts unter IR-Beleuchtung verursachen die reflektierenden Streifen Probleme.
| Kleidungstyp | Tageslichtgenauigkeit | Nacht-IR-Genauigkeit | Hauptproblem |
|---|---|---|---|
| Standardarbeitskleidung | 98% | 97% | Keine signifikanten |
| Warnweste | 99% | 93% | Blendung durch reflektierende Streifen |
| Sperriger Winterparka | 95% | 96% | Verzerrung der Körperform |
| Parka + Warnweste | 96% | 91% | Kombinierte Blendung + Verzerrung |
Wie wir Blendung durch reflektierende Streifen handhaben
Der Prozess beinhaltet die Identifizierung kleiner gesättigter Flecken auf dem Sensor. Unser 3D-Rauschunterdrungsalgorithmus4 identifiziert diese Hotspots und unterdrückt sie über mehrere Frames hinweg. Er rekonstruiert die Körperform unter der Blendung, indem er sich auf benachbarte Frames bezieht, in denen der Reflexionswinkel unterschiedlich ist.
Für Standorte, an denen alle Arbeiter Warnkleidung tragen, empfehle ich, den “Anti-Glare”-Modus in den Kameraeinstellungen zu aktivieren. Dies reduziert die IR-Leistung leicht und aktiviert automatisch die Multi-Frame-Rekonstruktionspipeline.
Kann die KI immer noch eine menschliche Form erkennen, wenn sie einen locker sitzenden gelben Regenmantel trägt?
Ich habe dieses Szenario selbst während eines Einsatzes in der Regenzeit getestet. Ein Arbeiter in einem langen gelben Poncho durchquerte das Sichtfeld der Kamera. Die erste Firmware-Version hat ihn zweimal übersehen. Nachdem wir das Modell mit Regenmantel-spezifischen Trainingsdaten aktualisiert hatten, hat es ihn jedes Mal erfasst.
Ja, aber die Genauigkeit sinkt bei Regenmänteln im Cape-Stil auf etwa 90% im Vergleich zu 98% bei normaler Kleidung. Die KI gleicht dies durch die Verwendung von Kopf-Schulter-Erkennung und Bewegungsbahnanalyse aus. Wenn die Körpersilhouette verborgen ist, verfolgt das System das Bewegungsmuster, um die Anwesenheit eines Menschen zu bestätigen.
![]() KI identifiziert menschliche Form in locker sitzendem gelbem Regenmantel
KI identifiziert menschliche Form in locker sitzendem gelbem Regenmantel
Warum Regenmäntel die größte Herausforderung darstellen
Ein locker sitzender Regenmantel verursacht drei gleichzeitige Probleme für die KI-Erkennung:
- Formzerstörung. Der Poncho verdeckt Taille, Hüften und Beine. Die menschliche Silhouette wird zu einer Dreiecks- oder Glockenform.
- Textur-Uniformität. Die glatte Kunststoffoberfläche weist keine Texturvariationen auf. Normale Kleidung hat Falten, Nähte und Muster, die der KI helfen zu bestätigen: “Das ist Stoff auf einem Körper”. Ein Regenmantel ist eine flache, formlose Oberfläche.
- Windbewegung. Im Wind flattert der Regenmantel und ändert von Frame zu Frame seine Form. Dies verwirrt bewegungsbasierte Algorithmen, die konsistente Objektgrenzen erwarten.
Unsere Multi-Layer-Detection-Strategie
Wir verlassen uns nicht auf eine einzige Erkennungsmethode. Unser System führt drei parallele Prüfungen durch:
Ebene 1: Kopf-Schulter-Modell. Selbst in einem vollen Poncho ragt der Kopf heraus. Die Kapuze bildet eine erkennbare Kuppelform. Die Schultern zeigen sich immer noch als horizontale Linie unter dem Kopf. Allein dies gibt uns eine Erkennungssicherheit von 85%.
Ebene 2: Bewegungsbahnanalyse. Menschen gehen in vorhersehbaren Mustern. Sie bewegen sich mit 3-6 km/h. Sie folgen Pfaden. Sie stoppen und ändern die Richtung mit spezifischen Beschleunigungskurven. Eine Plastiktüte, die im Wind weht, bewegt sich erratisch. Eine Person in einem Regenmantel geht immer noch wie eine Person. Unser Algorithmus verfolgt die Flugbahn des Objekts über 15-20 Frames und vergleicht sie mit menschlichen Bewegungsmodellen.
Ebene 3: Thermische Signatur (für IR-ausgestattete Modelle). Unter dem Regenmantel strahlt die Person immer noch Körperwärme ab. Im IR-Modus kann die Kamera die thermische Kontur des Körpers unter der Kunststoffschicht erkennen. Dies ist besonders effektiv bei unseren Modellen, die ungekühlte VOx-Mikrobolometersensoren verwenden5.
Negativbeispiel-Training
Wir haben unser Modell speziell mit Tausenden von “verwirrenden” Beispielen trainiert:
- Plastikplanen, die im Wind wehen (sollten NICHT auslösen)
- Müllsäcke an Zäunen (sollten NICHT auslösen)
- Personen in Ponchos (sollten auslösen)
- Personen unter Regenschirmen (sollten auslösen)
- Vogelscheuchen auf Feldern (sollten NICHT auslösen)
Dieser Ansatz mit negativen Beispielen6 lehrt das Modell, was ein Mensch NICHT ist, was genauso wichtig ist wie das Lehren, was ein Mensch IST.
Praktische Empfehlung
Für Standorte mit häufigem Regen (wie Baustellen in Texas oder Südostasien) empfehle ich die Aktivierung des Dual-Logic-Modus7: Bewegungserkennung + menschliche Erkennung kombiniert. Wenn die KI-Konfidenz für “Mensch” unter 80 % fällt, aber Bewegung erkannt wird, zeichnet das System das Ereignis immer noch auf und markiert es als “vermutetes Risiko”. Sie erhalten das Filmmaterial. Sie verpassen keine Eindringlinge. Und Sie können es später überprüfen.
Wird die Erkennungsstabilität durch die Farbe der Kleidung des Ziels vor dem Hintergrund beeinflusst?
Diese Lektion habe ich auf die harte Tour gelernt. Ein Kunde installierte Kameras, die ein grünes Feld überblickten. Arbeiter in grünen Uniformen waren für die grundlegende Bewegungserkennung fast unsichtbar. Die KI-Schicht hat sie erfasst, aber nur mit 60 % der normalen Reichweite. Der Hintergrundkontrast ist wichtiger, als die meisten Leute denken.
Ja, die Farbe der Kleidung im Verhältnis zum Hintergrund beeinflusst direkt die Erkennungsreichweite und -geschwindigkeit. Wenn die Kleidung eines Ziels mit der Hintergrundfarbe übereinstimmt, kann die Erkennungsreichweite um 20-30 % sinken. Unser System kompensiert dies durch Multi-Feature-Fusion – die Kombination von Farb-, Textur-, Bewegungs- und Wärmedaten –, um auch in Szenarien mit geringem Kontrast eine stabile Erkennung zu gewährleisten.
 Kleiderfarbenkontrast beeinflusst KI-Erkennung gegen Hintergrund
Kleiderfarbenkontrast beeinflusst KI-Erkennung gegen Hintergrund
Wie Farbkontrast die Erkennung beeinflusst
Das KI-Modell verarbeitet Bilder als Pixel-Arrays. Wenn die Kleidung einer Person in Farbe und Helligkeit dem Hintergrund ähnelt, wird die Kante zwischen “Person” und “Hintergrund” schwach. Das Modell benötigt starke Kanten, um Objektgrenzen zu definieren.
Stellen Sie es sich so vor: Eine Person in einer schwarzen Jacke vor einer dunklen Wand ist selbst für das menschliche Auge schwer zu erkennen. Die Kamera steht vor der gleichen Herausforderung, aber sie verfügt über Werkzeuge, die Menschen nicht haben.
Das Kontrastproblem nach Szenario
| Szenario | Kontraststufe | Erkennungsauswirkung | Kompensationsmethode |
|---|---|---|---|
| Dunkle Kleidung + dunkler Hintergrund | Sehr gering | Reichweite um 25-30% reduziert | IR-Beleuchtung + Wärme |
| Grüne Kleidung + Vegetation | Niedrig | Reichweite um 20-25% reduziert | Bewegungsvektoranalyse |
| Weiße Kleidung + Schnee | Niedrig | Reichweite um 15-20% reduziert | Schattenerkennungsalgorithmus |
| Jede Kleidung + neutrale Wand | Hoch | Keine Auswirkung | Standarderkennung |
| Warnkleidung + beliebiger Hintergrund | Sehr hoch | Reichweite um 10% erhöht | N/A (natürlicher Vorteil) |
Unsere Kompensationstechniken
1. Adaptives Hintergrundmodellierung
Die Kamera baut kontinuierlich ein Hintergrundmodell auf. Sie lernt, wie die “leere Szene” im Laufe der Zeit aussieht. Wenn sich etwas ändert – selbst um wenige Pixelwerte –, markiert das System es. Dies funktioniert auch bei minimalen Farbunterschieden, da das Modell subtile Texturänderungen erkennt, die eine reine Farbanalyse übersehen würde.
2. Kantenschärfungsverarbeitung
Unsere ist der Chip, der das Rohbild vom Sensor verarbeitet.8 wendet eine Echtzeit-Kantenschärfung an, wenn sie Regionen mit geringem Kontrast erkennt. Sie verstärkt die Schärfe von Grenzen zwischen Objekten. Dies liefert dem KI-Modell stärkere Kanteninformationen, auch wenn der Farbkontrast schlecht ist.
3. IR-Modus als der große Gleichmacher
Nachts wandelt der IR-Strahler alles in Graustufen um. Die Farbe der Kleidung wird irrelevant. Wichtig ist die Reflektivität – wie viel IR-Licht von der Oberfläche zurückprallt. Die meisten Stoffe reflektieren IR-Licht anders als natürliche Hintergründe (Blätter, Erde, Beton). So wird selbst eine grüne Jacke vor grünen Büschen im IR-Modus deutlich sichtbar, da der Stoff IR anders reflektiert als Blätter.
4. Mehrbild-Bewegungsakkumulation
Wenn ein einzelnes Bild nicht genügend Kontrast für die Erkennung liefert, sammelt unser Algorithmus Bewegungsdaten über 5-10 Bilder. Er erstellt eine “Bewegungshitmap”, die zeigt, wo Bewegung stattgefunden hat. Selbst ein Ziel mit geringem Kontrast erzeugt über die Zeit eine klare Bewegungspur. Diese Technik tauscht Geschwindigkeit gegen Genauigkeit – die Erkennung kann 0,5 Sekunden länger dauern, aber sie erfasst Ziele, die eine Einzelbildanalyse übersehen würde.
Meine Empfehlung für Standorte mit geringem Kontrast
Wenn Ihr Einsatzort bekannte Kontrastprobleme aufweist (grüne Vegetation, dunkle Industriegebiete, schneebedecktes Gelände), empfehle ich zwei Dinge:
- Positionieren Sie Kameras dort, wo Ziele Zonen mit hohem Kontrast kreuzen müssen (Wege, Zäune, freie Flächen).
- Aktivieren Sie den Modus “Empfindlichkeitsverstärkung”, der den Schwellenwert für die Erkennungssicherheit von 85 % auf 70 % senkt und dies durch Überprüfung der Bewegungstrajektorie kompensiert.
Diese Kombination hält Fehlalarme niedrig und stellt gleichzeitig sicher, dass Sie keine echten Eindringlinge verpassen, nur weil jemand das falsche Hemd trug.
Schlussfolgerung
Die Erkennungsstabilität über Hauttöne und Kleidungstypen hinweg hängt vom dynamischen Bereich der Hardware, vielfältigen KI-Trainingsdaten und mehrschichtigen Erkennungsalgorithmen ab. Keine einzelne Methode löst jedes Szenario – das System benötigt WDR-Sensoren, Skelettpunkt-Erkennung, Fallback-Modelle für Kopf und Schultern sowie Bewegungsbahnanalyse, die zusammenarbeiten. Wenn Sie diese Fähigkeiten unter Ihren spezifischen Standortbedingungen testen möchten, kontaktieren Sie mich unter sales05@.com und ich arrangiere eine reale Demo mit Ihrem genauen Anwendungsfall.
1. Die Skelettpunkt-Erkennung extrahiert wichtige Körpergelenke (Kopf, Schultern, Ellbogen), um Menschen unabhängig von Hautfarbe oder Kleidung zu erkennen. ︎↩︎ 2. Die Fitzpatrick-Skala von I (sehr hell) bis VI (sehr dunkel) wird in der Dermatologie und bei der KI-Fairness verwendet, um ausgewogene Trainingsdaten sicherzustellen. ︎↩︎ 3. Wide Dynamic Range (WDR)-Sensoren mit 120 dB erfassen Details in hellen und dunklen Bereichen, was für die Ausgleichung der Belichtung von menschlichen Gesichtern entscheidend ist. ︎↩︎ 4. Die 3D-Rauschunterdrückung verarbeitet mehrere Bilder, um Hotspots zu unterdrücken und klare Bilder zu rekonstruieren, insbesondere bei reflektierender Kleidung unter IR. ︎↩︎ 5. Vanadiumoxid (VOx)-Mikrobolometer erkennen Wärmesignaturen und ermöglichen Wärmebildgebung durch Regenmäntel und andere verdeckende Kleidung. ︎↩︎ 6. Das Training mit negativen Beispielen lehrt die KI, was NICHT erkannt werden soll (z. B. Planen, Müllsäcke), wodurch Fehlalarme bei mehrdeutigen Objekten reduziert werden. ︎↩︎ 7. Der Dual-Logic-Modus kombiniert Bewegungserkennung mit menschlicher Erkennung und löst Alarme aus, auch wenn die KI-Konfidenz unter dem Schwellenwert liegt, was bei regnerischen Bedingungen nützlich ist. ︎↩︎ 8. Die ISP wendet eine Echtzeit-Kantenschärfung an, um Grenzen in kontrastarmen Szenen zu schärfen und die KI-Erkennung zu unterstützen. ︎↩︎