
He visto módulos 4G congelarse en el campo. La cámara permanece encendida, pero la red está muerta. Nadie puede acceder a ella. Conduces horas hasta el sitio solo para desconectar un cable y volver a conectarlo.
Sí, la placa base puede forzar un ciclo de reinicio de energía en un módulo 4G bloqueado, pero solo si el diseño del hardware incluye un circuito de interruptor de alimentación dedicado y un MCU de vigilancia independiente1. Sin estas dos características, un módulo 4G congelado permanecerá congelado hasta que alguien corte la alimentación físicamente.
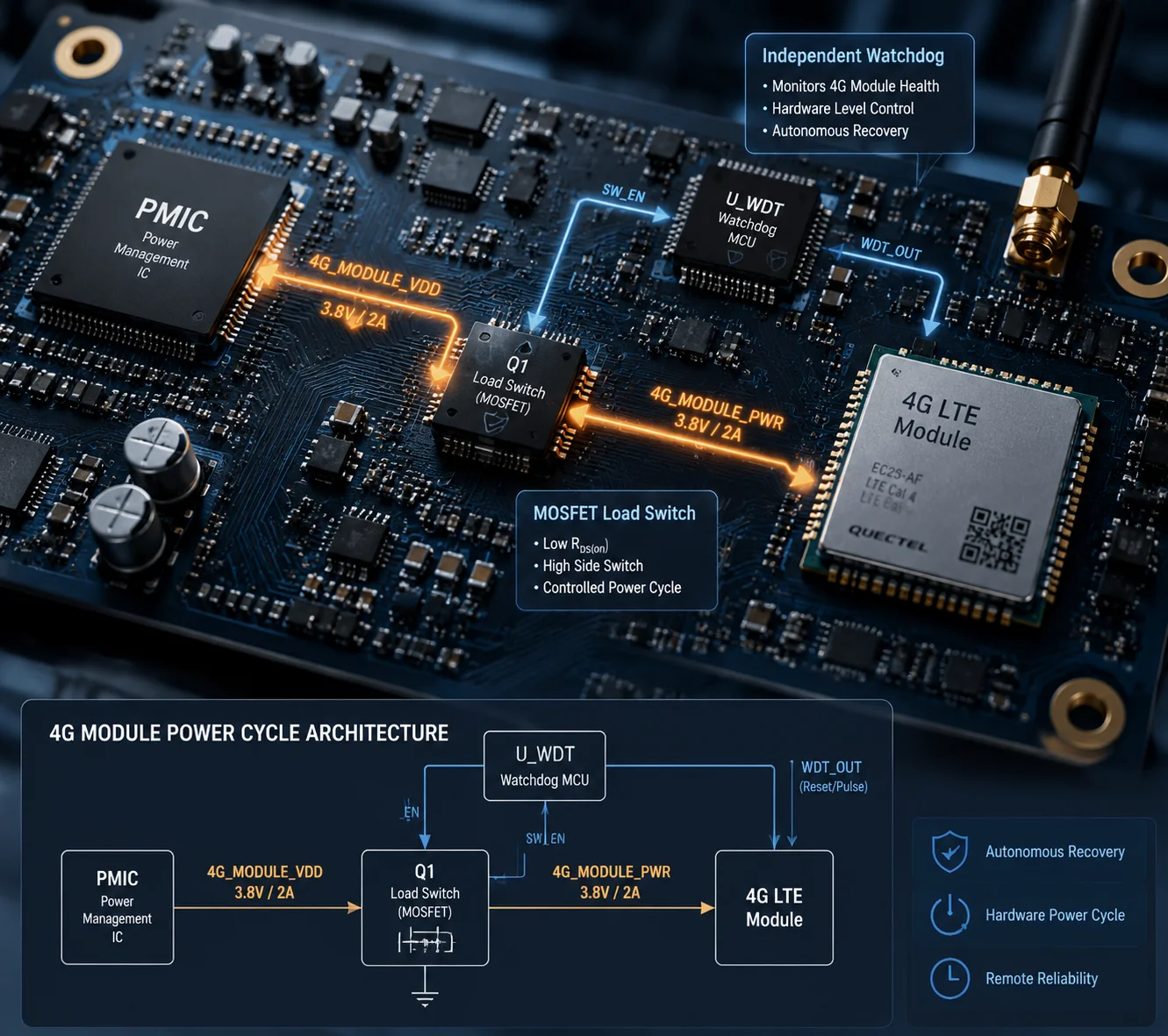 Ciclo de reinicio de energía del módulo 4G placa base cámara PTZ de vigilancia
Ciclo de reinicio de energía del módulo 4G placa base cámara PTZ de vigilancia
La mayoría de las placas PTZ de bajo costo no tienen esta capacidad. Tratan el módulo 4G como un periférico simple. Cuando el módulo se bloquea, el procesador principal no tiene forma de cortar su alimentación. Todo el sistema debe reiniciarse, o peor aún, alguien debe visitar el sitio. En este artículo, desglosaré exactamente cómo una placa base diseñada correctamente detecta un módem congelado, corta su alimentación y lo devuelve a la vida, todo sin intervención humana.
Índice
¿Cómo detecta el “Circuito Integrado de Gestión de Energía” (PMIC) un módem congelado que todavía consume corriente?
Un módulo 4G congelado es complicado. Todavía consume corriente del riel de alimentación. Los LED pueden seguir encendidos. Desde fuera, parece vivo. Pero no responde a nada.
La placa base no se basa únicamente en la detección de corriente. En cambio, una MCU de bajo consumo envía periódicamente comandos AT2 al módulo 4G a través de UART3. Si el módulo no responde después de varios intentos consecutivos, la MCU lo declara “muerto” y activa la secuencia de corte de energía.
 PMIC vigilancia MCU detección de latidos del módulo 4G
PMIC vigilancia MCU detección de latidos del módulo 4G
Por qué el monitoreo de corriente por sí solo no es suficiente
Podrías pensar: “Si el módulo falla, su consumo de corriente cambiará”. A veces lo hace. Pero en muchos escenarios de fallo, el módulo sigue consumiendo 200-400 mA, un consumo en reposo perfectamente normal. El PMIC no ve nada malo. El riel de voltaje se mantiene estable. La corriente parece normal. Pero el firmware del módulo está atascado en un bucle infinito o un bloqueo del stack de protocolos.
Es por eso que los buenos diseños utilizan un detección basada en latidos4 método en lugar de, o además de, la monitorización actual.
Cómo funciona el sistema de latidos
Aquí está el flujo de detección típico:
| Paso | Acción | Tiempo de espera agotado |
|---|---|---|
| 1 | El MCU envía AT comando por UART | Espera 3 segundos para obtener respuesta |
| 2 | Sin respuesta → El MCU reintenta | Reintenta hasta 5 veces (15 segundos en total) |
| 3 | Todos los reintentos fallan → El MCU envía AT+CFUN=1,1 (reinicio suave) | Espera 60 segundos para que el módulo se vuelva a registrar |
| 4 | Todavía sin respuesta → El MCU activa un ciclo de energía forzado | Corta VCC durante 2–5 segundos, luego restaura |
El MCU funciona con su propio reloj. No depende del procesador principal de Linux. Incluso si la CPU principal también se cuelga, el MCU de vigilancia sigue funcionando. Es un circuito completamente independiente, a menudo un chip diminuto como un STM8 o un LPC810 que cuesta menos de 0,50 $.
El papel del PMIC en este proceso
El PMIC en sí no “decide” cortar la energía. Simplemente proporciona los rieles de voltaje. El que toma la decisión es el MCU de vigilancia. El MCU controla un interruptor de carga MOSFET5 situado entre la salida del PMIC y la entrada VCC del módulo 4G. Cuando el MCU pone la puerta del MOSFET en alto, el interruptor se abre. La energía del módulo cae a cero. Después de un retraso programado (generalmente 2–5 segundos), el MCU libera la puerta. La energía regresa. El módulo se inicia en frío desde cero.
Por qué la demora es importante
No puedes simplemente apagar y encender la alimentación al instante. El módulo 4G tiene condensadores internos. Si restauras la alimentación demasiado rápido, esos condensadores aún retienen carga residual. El estado interno del módulo no se borra por completo. Podría arrancar de nuevo en el mismo estado fallido. Una demora de 2 a 5 segundos asegura que cada condensador se descargue por completo. El módulo vuelve a una condición real de “encendido de fábrica”. Esta es la diferencia entre un reinicio real y uno falso.
En nuestros diseños en Loyalty-Secu, establecemos esta demora en 3 segundos por defecto. Probamos demoras más cortas y descubrimos que algunos módulos, especialmente en climas fríos, necesitan los 3 segundos completos para descargarse correctamente.
¿Hay un “Pin de Reinicio” dedicado conectado entre la CPU y el hardware del módulo 4G?
Solía pensar que el pin RESET era suficiente. Bajarlo, esperar un momento, soltarlo y el módulo se reinicia. Funciona, la mayor parte del tiempo. Pero “la mayor parte del tiempo” no es suficiente para una cámara en un poste en medio del desierto.
Sí, la mayoría de los módulos 4G tienen un pin de hardware RESET6, y una placa base bien diseñada lo conectará a un GPIO en la CPU principal o MCU de vigilancia. Pero el pin RESET es solo la primera línea de defensa. No puede solucionar todos los fallos. Un corte total de alimentación VCC es la última opción de respaldo.
 Pin de reinicio del módulo 4G conexión GPIO PWRKEY placa base
Pin de reinicio del módulo 4G conexión GPIO PWRKEY placa base
Lo que hace realmente el pin RESET
El pin RESET activa un reinicio interno del procesador del módulo. Es similar a presionar el botón de reinicio en tu computadora. El firmware del módulo se recarga desde la memoria flash. El procesador de banda base se reinicializa. El registro de red comienza de nuevo.
Para la mayoría de los fallos a nivel de software, como un proceso de marcación atascado o un tiempo de espera agotado en la búsqueda de DNS, esto funciona bien. El módulo vuelve a estar en línea en 20-40 segundos.
Cuando el pin RESET falla
Pero hay situaciones en las que el pin RESET no puede ayudar:
| Tipo de fallo | Qué ocurre | ¿Puede el pin RESET solucionarlo? |
|---|---|---|
| Bloqueo (Latch-up) | La descarga estática o un pico de voltaje causa un efecto SCR parásito dentro del módulo. La corriente fluye a través de caminos no deseados. | ❌ No. El circuito interno está eléctricamente bloqueado. Solo un corte total de alimentación puede romper el bloqueo. |
| Bloqueo por subtensión (brownout) | El módulo intentó transmitir a alta potencia, la corriente se disparó, el voltaje cayó por debajo del mínimo y el módulo entró en un estado indefinido. | ❌ No. El módulo está atascado entre “encendido” y “apagado”. La lógica de RESET en sí misma puede no funcionar a este voltaje. |
| Corrupción de Flash | Un pico de energía durante una escritura de firmware corrompió el sector de arranque. El módulo no puede cargar su firmware en absoluto. | ❌ No. El módulo entra en un bucle infinito en la etapa del cargador de arranque. RESET simplemente reinicia el mismo bucle roto. |
En los tres casos, la única solución es quitar completamente la alimentación del módulo. Por eso, un interruptor de carga MOSFET en la línea VCC no es opcional, es esencial.
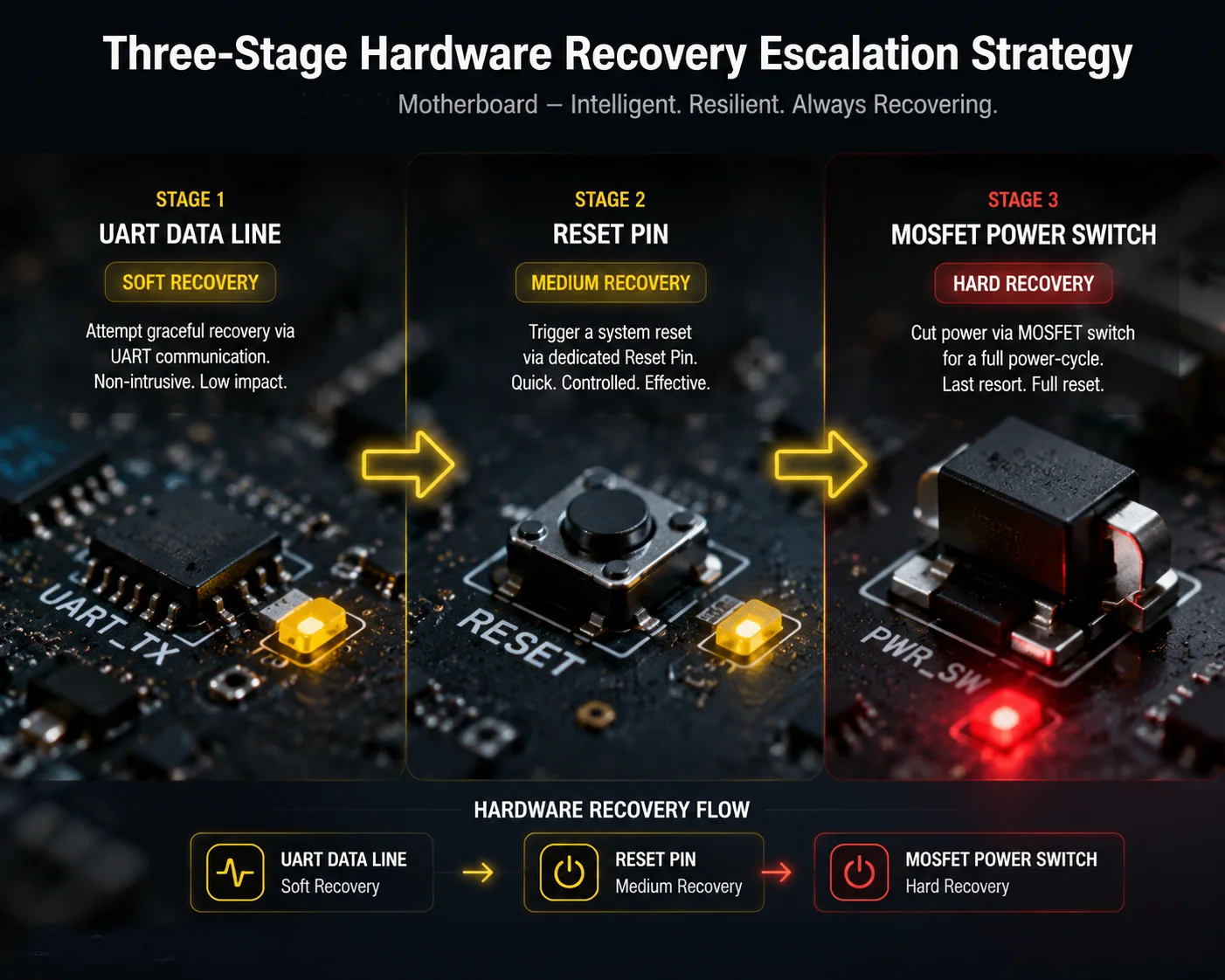
La Estrategia de Recuperación en Tres Etapas
Una placa base diseñada correctamente utiliza una escalada en tres etapas:
- Etapa 1 — Reinicio Suave: Enviar
AT+CFUN=1,1oAT+QPOWD=0a través de UART. Esto pide al módulo que se reinicie amablemente. Espere 60 segundos. - Etapa 2 — Reinicio de Pin: Poner el pin RESET o PWRKEY en bajo durante 1 segundo, luego soltar. Esto fuerza un reinicio a nivel de hardware sin cortar la alimentación. Espere 60 segundos.
- Etapa 3 — Ciclo de Alimentación Forzado: Cortar VCC a través del interruptor MOSFET. Mantener durante 3 segundos. Restaurar la alimentación. Espere 90 segundos para el arranque completo y el registro en la red.
Si la Etapa 3 también falla después de 3 intentos consecutivos en 10 minutos, el sistema debe dejar de intentarlo y registrar una falla crítica de hardware. Esto evita un bucle de reinicio infinito que podría dañar el módulo o agotar una batería solar.
En Loyalty-Secu, conectamos tanto el pin RESET como el pin PWRKEY7 1. para separar los GPIO en la MCU del watchdog. Esto nos da control independiente sobre cada señal. No las enrutamos a través del procesador principal de Linux, porque si Linux mismo falla, todavía necesitamos que el watchdog actúe.
¿Evitará esta función los “Dispositivos Zombis” que permanecen encendidos pero son inalcanzables?
“2. ”Dispositivos zombis", — eso es exactamente lo que mis clientes los llaman. El panel solar sigue cargando. El cuerpo de la cámara permanece caliente. El LED de estado parpadea en verde. Pero el enlace 4G está muerto. El dispositivo es un fantasma en la red. No puedes verlo. No puedes controlarlo. Simplemente está ahí, consumiendo energía y sin hacer nada.
3. Sí, una placa base con un watchdog independiente y un circuito de interruptor de alimentación 4G eliminará los dispositivos zombis. El watchdog detecta el fallo de comunicación en 90 segundos y fuerza un ciclo de alimentación completo. En la mayoría de los casos, el módulo 4G se recupera y se vuelve a registrar en la red en 3 minutos, sin intervención humana.
 4. dispositivo zombi solar PTZ cámara módulo 4G recuperación automática
4. dispositivo zombi solar PTZ cámara módulo 4G recuperación automática
5. Por qué los dispositivos zombis son tan caros
6. El dispositivo en sí podría costar entre 300 y 500 dólares. Pero el costo de un dispositivo zombi es mucho mayor que eso. Considere este escenario: despliega 50 cámaras PTZ solares a lo largo de un oleoducto de 200 kilómetros en el oeste de Texas. Tres meses después, 4 de ellas se quedan a oscuras. Su centro de monitoreo no ve nada de esos 4 sitios. Envía un técnico. El viaje dura 6 horas ida y vuelta. El técnico llega, desenchufa el cable de alimentación, espera 10 segundos, lo vuelve a enchufar. La cámara vuelve a estar en línea. Costo total de esa visita de “desenchufar y volver a enchufar”: entre 800 y 1200 dólares en mano de obra, combustible y pérdida de productividad.
7. Ahora multiplique eso por 4 cámaras. Y sucede de nuevo al mes siguiente. Y al mes siguiente.
8. Cómo funciona el bucle de recuperación automática
9. Una placa base con un diseño de watchdog adecuado ejecuta un bucle de monitoreo continuo:
- 10. Cada 10 segundos, la MCU del watchdog verifica si el módulo 4G responde a un comando básico.
AT11. Cada 30 segundos, verifica si el módulo tiene una dirección IP válida y puede llegar al servidor en la nube (a través de un ping ligero o keepalive MQTT). - 12. Si ambas verificaciones fallan durante 90 segundos consecutivos, comienza la secuencia de recuperación.
- 13. Qué sucede durante la recuperación.
14. El sistema sigue la escalada de tres etapas que describí anteriormente. Pero hay una adición importante para la prevención de zombis:
15. el watchdog también monitorea la recuperación en sí. 16. Si el módulo vuelve a estar en línea pero se cae nuevamente en 5 minutos, el watchdog cuenta esto como una "recuperación inestable". Después de 3 recuperaciones inestables, el sistema cambia a un.
17. . Apaga completamente el módulo 4G y espera 30 minutos antes de intentarlo de nuevo. Esto evita el consumo de batería en sistemas alimentados por energía solar. modo de espera de bajo consumo. 18. Impacto en el mundo real en los costos de mantenimiento.
19. Sin ciclo de alimentación automático
| Escenario | Sin Ciclo Automático de Encendido | Con Ciclo de Encendido Automático |
|---|---|---|
| Visitas anuales al sitio por cada 50 cámaras | 30–50 visitas | 2–5 visitas (solo para fallos reales de hardware) |
| Costo promedio por visita | 800–1,200 USD | 800–1,200 USD |
| Costo anual de mantenimiento | 24,000–60,000 USD | 1,600–6,000 USD |
| Tiempo de actividad del dispositivo | 85–92 % | 98–99.5 % |
Estas cifras provienen de comentarios reales que recibimos de integradores que implementan nuestros sistemas solares PTZ en áreas remotas de Oriente Medio y América del Norte. La función de ciclo de encendido automático por sí sola puede reducir los costos anuales de mantenimiento de campo en un 80 % o más.
La Promesa de “Cero Mantenimiento”
Para implementaciones fuera de la red —cámaras alimentadas por energía solar en granjas, sitios de construcción, campos petroleros o acantilados costeros— esta función es lo que hace posible el “cero mantenimiento”. La cámara se cuida sola. Detecta su propio fallo 4G. Se repara sola. Registra el evento. Y vuelve al trabajo. Sin llamada telefónica. Sin desplazamiento de técnico. Sin tiempo de inactividad.
¿Registra la placa base estos eventos de “fallo y recuperación” para mi auditoría técnica?
Cuando hablo con los integradores de sistemas, siempre hacen la misma pregunta después de que explico la función de autorrecuperación: “¿Eso suena genial, pero puedo ver qué pasó?”. Necesitan pruebas. Necesitan registros. Sus clientes finales —agencias gubernamentales, compañías de servicios públicos, empresas de construcción— requieren pistas de auditoría.
Sí, una placa base bien diseñada registra cada evento de caída y recuperación con una marca de tiempo, el tipo de fallo, la etapa de recuperación que tuvo éxito y la intensidad de la señal del módulo antes y después del evento. Estos registros se almacenan localmente y se pueden enviar a un servidor en la nube a través de MQTT o HTTP.
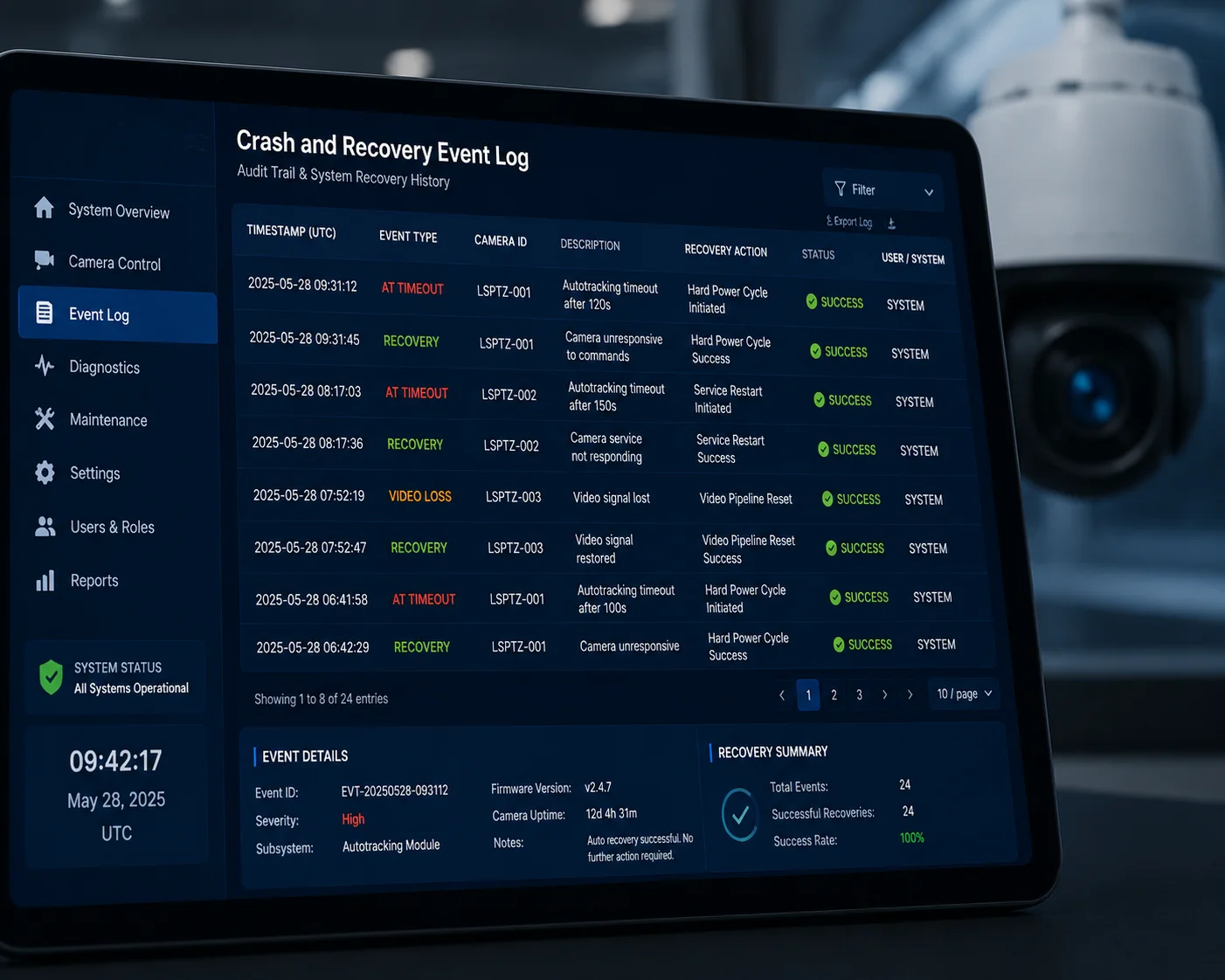 registro de eventos de recuperación de fallos 4G cámara PTZ pista de auditoría
registro de eventos de recuperación de fallos 4G cámara PTZ pista de auditoría
Qué se registra
El MCU watchdog y el procesador principal trabajan juntos para registrar datos detallados de eventos. Una entrada de registro típica incluye:
- Marca de tiempo: Fecha y hora de la falla detectada (sincronizada vía NTP o GPS).
- Tipo de falla: Tiempo de espera AT, pérdida de latido, error UART o IP inalcanzable.
- Etapa de recuperación: Qué etapa solucionó el problema: reinicio suave, reinicio de pin o ciclo de energía completo.
- Duración: Cuánto tiempo estuvo el módulo desconectado antes de que se completara la recuperación.
- Calidad de la señal: Valores RSSI y SINR antes del fallo y después de la recuperación.
- Conteo acumulado: Número total de ciclos de energía desde el último arranque del sistema.
Estos registros se almacenan localmente y se pueden enviar a un servidor en la nube a través de MQTT8 o HTTP.
Por qué los registros importan para su negocio
Si usted es un integrador de sistemas que vende un contrato de mantenimiento de 3 años, necesita demostrar que su sistema es confiable. Cuando su cliente pregunta: “¿Por qué la Cámara 17 estuvo desconectada durante 4 minutos el martes pasado a las 3 AM?”, usted necesita una respuesta. Sin registros, no tiene nada. Con registros, puede mostrarles: “El módulo 4G perdió su registro de red debido a un traspaso de estación base. El perro guardián detectó la falla en 90 segundos. Un reinicio suave lo resolvió. Tiempo total de inactividad: 3 minutos y 42 segundos. No se perdieron datos porque la cámara almacenó en caché 4 minutos de video localmente y lo subió después de la recuperación”.”
Ese nivel de transparencia genera confianza. Convierte una queja potencial en una prueba de calidad.
Cómo acceder a los registros
La mayoría de los sistemas ofrecen múltiples métodos de acceso:
- Interfaz web: Inicie sesión en la interfaz web local de la cámara y descargue el registro de eventos como un archivo CSV.
- Notificación push en la nube: La cámara envía cada evento a su plataforma en la nube a través de MQTT o HTTP POST en tiempo real.
- Eventos ONVIF: Algunos firmwares avanzados mapean estos eventos de recuperación a ONVIF9 notificaciones de eventos, para que su VMS (como Milestone o Blue Iris) pueda mostrarlos directamente.
- Almacenamiento local: Los registros también se escriben en la eMMC o tarjeta SD integrada, por lo que incluso si el enlace 4G está caído, los datos se conservan.
Qué preguntar a su proveedor
Cuando evalúe una cámara PTZ para implementación remota, haga estas preguntas específicas:
- “¿Tiene su placa base una MCU watchdog independiente que monitorea el módulo 4G?”
- “¿Puede el watchdog cortar físicamente la alimentación del módulo 4G, no solo enviar una señal de reinicio?”
- “¿Dónde se almacenan los registros de fallos y recuperación, y cómo puedo acceder a ellos de forma remota?”
- “¿Cuál es el número máximo de ciclos de encendido automáticos antes de que el sistema se detenga y marque un fallo de hardware?”
Si el proveedor no puede responder a estas preguntas con claridad, es probable que su placa no tenga esta función. Y eso significa que cada módulo 4G congelado requerirá una visita técnica.
En Loyalty-Secu, integramos estas capacidades en el diseño de nuestra placa base desde el principio. Nuestra MCU watchdog, el interruptor de alimentación MOSFET y la lógica de recuperación de tres etapas son estándar en todas nuestras plataformas PTZ solares 4G. También proporcionamos registros de eventos completos accesibles a través de nuestra API en la nube o la interfaz web local de la cámara. Como controlamos toda la cadena de suministro vertical, desde el diseño de PCB hasta el ensamblaje final, podemos personalizar el tiempo de espera del watchdog, los retrasos de recuperación y los formatos de registro para que coincidan con los requisitos de su proyecto.
Conclusión
Una placa base puede forzar un ciclo de encendido en un módulo 4G bloqueado, pero solo si tiene una MCU watchdog independiente y un interruptor de alimentación de hardware. Exija ambos en las especificaciones de su próximo proyecto.
1. Un microcontrolador dedicado que monitorea el estado del sistema y puede forzar un reinicio de hardware o un ciclo de encendido. ︎↩︎ 2. Comandos estandarizados utilizados para controlar módems, incluidos módulos celulares, a través de una interfaz serie. ︎↩︎ 3. Una interfaz de comunicación serie comúnmente utilizada para conectar microcontroladores a módems. ︎↩︎ 4. Una técnica de monitoreo que utiliza señales periódicas para verificar que un sistema o componente responde. ︎↩︎ 5. Un circuito basado en MOSFET que puede encender o apagar la fuente de alimentación de un dispositivo bajo control lógico. ︎↩︎ 6. Un pin de hardware en un microcontrolador o módulo que activa un reinicio de su lógica interna. ︎↩︎ 7. Un pin de control en módulos celulares que se pone a nivel bajo para iniciar una secuencia de encendido; a menudo se usa para reiniciar el módulo. ︎↩︎ 8. Un protocolo de mensajería ligero de publicación-suscripción diseñado para dispositivos IoT y redes de bajo ancho de banda. ︎↩︎ 9. Un estándar abierto para productos de seguridad basados en IP, que permite la interoperabilidad entre cámaras y sistemas de gestión de video. ︎↩︎